In this post I’ll try to share an idea I’ve had regarding pentest reports. Most of you surely have
their own methods and tools to create nice looking reports after have done some pentesting.
Since I try to keep things simple I’ll give you a rough idea how this could be done without Excel & Co.
Scenario
#
Suppose you conduct a pentest and take notes during it. Afterwards you’ll be probably be copy&paste’integratedP
the whole content into a layout or pre-defined document. But what if you could take notes and
use them as content for your report without changing anything? I usually have one file where I write
down my thoughts and findings. In the past I had to copy the relevant text paragraphs and include them
at the right place in my final document.
Wouldn’t be more comfortable to write down your notes only once and then generate the report upon
your notes? Well this is where pandoc comes in place.
pandoc
#
Short summary about this great tool:
Pandoc understands a number of useful markdown syntax extensions,
including document metadata (title, author, date); footnotes; tables;
definition lists; superscript and subscript; strikeout; enhanced ordered
lists (start number and numbering style are significant); running example lists;
delimited code blocks with syntax highlighting; smart quotes, dashes, and ellipses;
markdown inside HTML blocks; and inline LaTeX. If strict markdown compatibility is desired,
all of these extensions can be turned off.
Infact you can convert documents into (almost) every possible format and vice-versa! Isn’t that cool :)?
Make sure you have a look at the examples to get an
impression what this tool is capable of.
The idea…
#
I’ll try to explain the whole process using a figure:
Graphviz code
digraph {
node [shape=circle,fontsize=8,fixedsize=true,width=0.9];
edge [fontsize=8];
rankdir=LR;
"pandoc" [shape="doublecircle" color="orange"];
"output" [shape="doublecircle" color="orange"];
"Document 1" -> "pandoc";
"Document 2" -> "pandoc";
"Document 3" -> "pandoc";
"pandoc" -> "output" [label="convert"];
"output" -> "PDF";
"output" -> "HTML";
"output" -> "LaTeX";
"output" -> "XML";
}
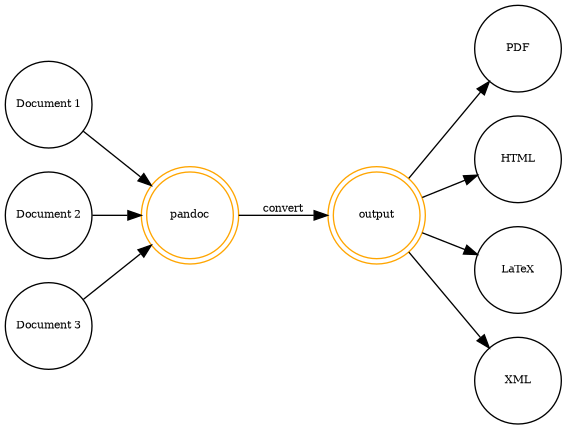
So take a document run it through pandoc and you’ll get a lot of possible output formats. Especially
the PDF output and the LaTeX will surely help you get the most out of your notes. You might
want to use XML as well if you tend to save your results in a DB to process them later on.
Quickstart
#
Let’s suppose we are done with our pentest and wrote down some notes. I’ll use Markdown for the
syntax since it is very easy to use and already integrated within GitHub & Co. The source file I’ll be
using:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
# Summary
## Host
http://dornea.nu
## Date
2014-03-10
# Vulns
## SQLi
### Description
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
### Severity
High
### PoC
* Input
~~~
<HTML><BODY>
<?xml:namespace prefix="t" ns="urn:schemas-microsoft-com:time">
<?import namespace="t" implementation="#default#time2">
<t:set attributeName="innerHTML" to="XSS<SCRIPT DEFER>alert("XSS")</SCRIPT>">
</BODY></HTML>
~~~
* Output
~~~
here comes the output
~~~
## Information Disclosure
### Description
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
### Severity
Low
### PoC
* Input
~~~
here ist the poc
~~~
|
Now we’ll be using pandoc in order to convert the notes into a parseable form like JSON or XML.
1
|
$ ~/.cabal/bin/pandoc -s -S -t docbook test.markdown -o test.xml
|
Convert to XML
#
This will convert you Markdown code into a DocBook based XML file. The output will be:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook XML V4.5//EN" "http://www.oasis-open.org/docbook/xml/4.5/docbookx.dtd">
<article>
<articleinfo>
<title></title>
</articleinfo>
<sect1 id="summary">
<title>Summary</title>
<sect2 id="host">
<title>Host</title>
<para>
http://dornea.nu
</para>
</sect2>
<sect2 id="date">
<title>Date</title>
<para>
2014-03-10
</para>
</sect2>
</sect1>
<sect1 id="vulns">
<title>Vulns</title>
<sect2 id="sqli">
<title>SQLi</title>
<sect3 id="description">
<title>Description</title>
<para>
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do
eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut
enim ad minim veniam, quis nostrud exercitation ullamco laboris
nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor
in reprehenderit in voluptate velit esse cillum dolore eu fugiat
nulla pariatur. Excepteur sint occaecat cupidatat non proident,
sunt in culpa qui officia deserunt mollit anim id est laborum.
</para>
</sect3>
<sect3 id="severity">
<title>Severity</title>
<para>
High
</para>
</sect3>
<sect3 id="poc">
<title>PoC</title>
<itemizedlist>
<listitem>
<para>
Input
</para>
<programlisting>
<HTML><BODY>
<?xml:namespace prefix="t" ns="urn:schemas-microsoft-com:time">
<?import namespace="t" implementation="#default#time2">
<t:set attributeName="innerHTML" to="XSS<SCRIPT DEFER>alert("XSS")</SCRIPT>">
</BODY></HTML>
</programlisting>
</listitem>
<listitem>
<para>
Output
</para>
<programlisting>
here comes the output
</programlisting>
</listitem>
</itemizedlist>
</sect3>
</sect2>
<sect2 id="information-disclosure">
<title>Information Disclosure</title>
<sect3 id="description-1">
<title>Description</title>
<para>
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do
eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut
enim ad minim veniam, quis nostrud exercitation ullamco laboris
nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor
in reprehenderit in voluptate velit esse cillum dolore eu fugiat
nulla pariatur. Excepteur sint occaecat cupidatat non proident,
sunt in culpa qui officia deserunt mollit anim id est laborum.
</para>
</sect3>
<sect3 id="severity-1">
<title>Severity</title>
<para>
Low
</para>
</sect3>
<sect3 id="poc-1">
<title>PoC</title>
<itemizedlist>
<listitem>
<para>
Input
</para>
<programlisting>
here ist the poc
</programlisting>
</listitem>
</itemizedlist>
</sect3>
</sect2>
</sect1>
</article>
|
You could now use this XML file to import your notes into a DB (e.g. SQLite) or easily convert it to other layouts using XSLT.
I usually use DB to store all my results. This way I’m able to use SQL
queries to extract data and keep a sort of history across the results.
Convert to PDF
#
Or if you’re a LaTeX freak like me you could use your favourite template and generate your PDF.
1
2
|
$ wget http://johnmacfarlane.net/pandoc/demo/mytemplate.tex
$ ~/.cabal/bin/pandoc -N --template=mytemplate.tex --variable fontsize=12pt --variable version=1.10 test.markdown --latex-engine=xelatex --toc -o test.pdf
|
And the result:
