This article is part of a series.
- Part 1: This Article
- Part 2: Migrate Tiddlywiki to org-roam - Part 2: org-roam and hugo
In the first part of this series I’ll outline the main factors why I’ve decided to move my digital garden / braindump / Zettelkasten to org-roam and which factors have facilitated this decision. In the 2nd part (still work in progress) I will expand more how I’ve built the new brainfck.org using hugo, ox-hugo and org-roam.
Motivation #
I’ve been using Tiddlywiki for almost 10 years now and setup different instances for work, personal stuff and lately as my own personal knowledge management system. I’ve used it to save highlights, notes, quotes from different sources and organized them in an useful way. I used daily journaling to handle the daily input of ideas and (web) articles I’m constantly exposed to. I talked at work about the importance of PKMS and how Tiddlywiki can increase productivity and contribute to better (mental) health by using it as a second brain. Other popular terms: Zettelkasten (slip box in German), memex, braindump or digital garden. Basically it’s all about giving your a brain a rest and offload information to a medium so your brain doesn’t have to remember everything:
Your brain is for having ideas, not for holding them – Getting Things Done
While I initially started using just one single HTML file for my tiddlers, I soon switched over to the nodeJS installation. This still has better benefits like:
- you can run the instance in Docker
- install
tiddlywikiand its dependencies without messing around with your system
- install
- you’ll get multiple “flat” files (
.tidfiles are in plain text)- you can apply
sed,awk,bashfoo to extract/modify data - even if Tiddlywiki will be discontinued some day, you’ll still be able to import your notes in whatever note-taking syntax
- you can apply
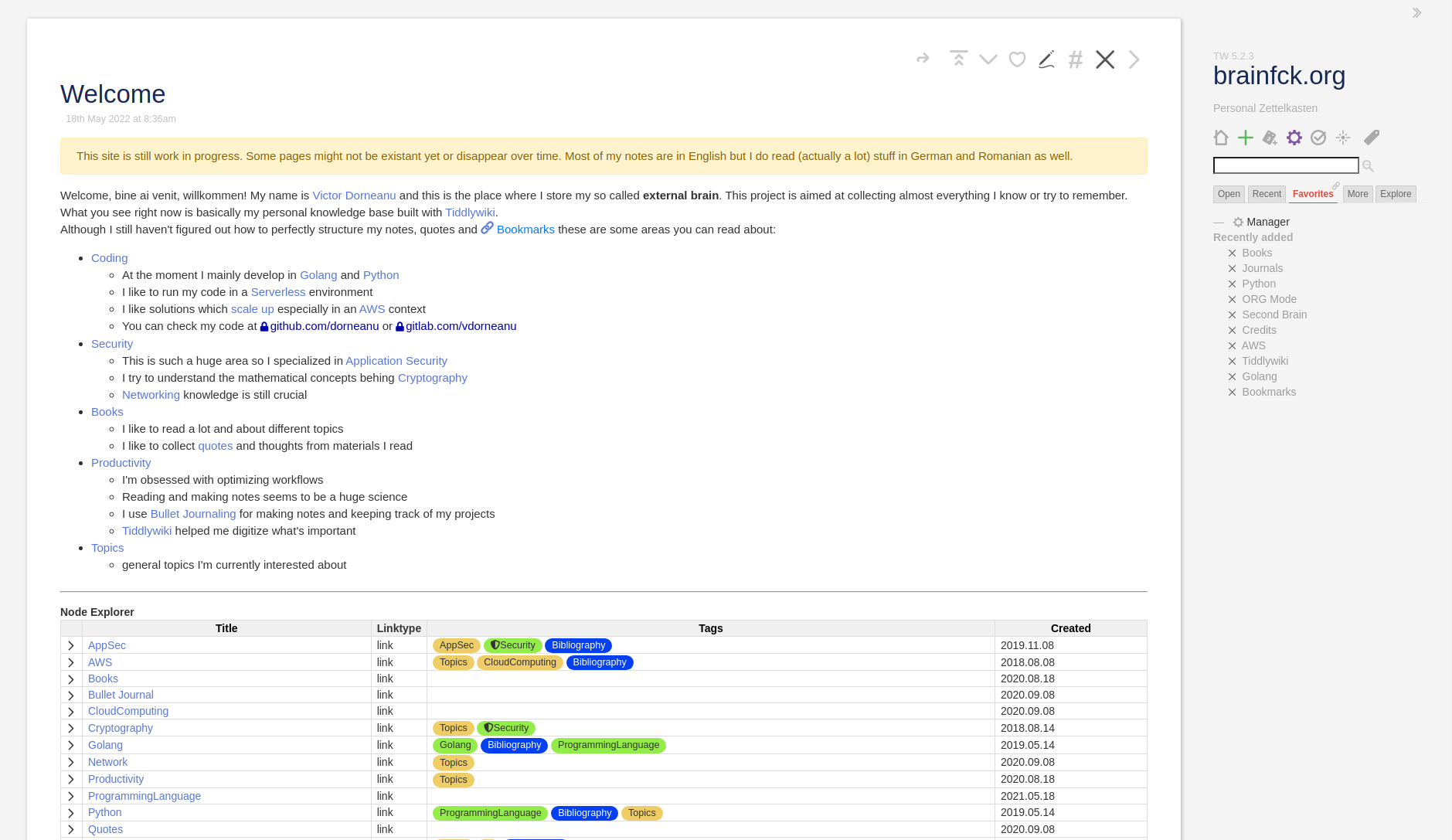
Among the many packages I’ve used, stroll has definitely changed the way I interacted with Tiddlywiki. It allowed me to focus more on the note-taking process by dividing the screen into 2 columns. This allowed me to work on different tiddlers simultaneously. Still it took me hours to process my notes and digitize them into Tiddlywiki. I guess the UI kind of slowed me down, mostly because I’m a keyboard-centric user and don’t use the mouse that often. Switching between tiddlers, closing them, creating new ones always involved mouse interaction.
For the same reason I’ve been using VIM for more than a decade and since more than 2 years I’m happy to consider myself an evil Emacs user. It became not only my primary editor, but also my RSS feeds reader, mail client, YouTube video player, IDE, API client… I basically live in Emacs Here is my config.org and try to avoid as many context switches as possible.
Personal preferences #
ORG mode as lingua franca #
After going down the Emacs rabbit hole, I’ve adopted ORG mode as my main file format for writing documents, exporting these to other formats (PDF, markdown, Confluence, Jira and many others), creating diagrams (mainly plantuml), presentations, writing technical documentation and hopefully some day for publishing a whole book. For the note-taking phase I write my notes in ORG mode and create a rudimentary outline sorted by chapters/sections. Usually I use the same structure to create my blog posts from (like I did in the book summaries). Extracting pieces of information for individual tiddlers, however, tends to be a time-intensive process. I’ve managed to use the Tiddlywiki API within Emacs but my Elisp skills are still not good for doing more advanced stuff like:
- fetch existing tiddlers, modify body in a new buffer, save new tiddler
- when linking text to new/existing tiddler, show list (in the minibuffer) of Tiddlers and if not create new one(s)
- show cross-references (e. g. Backlinks) for a specific tiddler
- refile specific (ORG) headline to a new tiddler
All these features are some however doable within Tiddlywiki using stroll and streams. But I don’t want to use the web UI anymore since I’m already inside Emacs for the majority of the day 😅
Editing on steroids #
At some point I began adopting ORG style syntax for the new tiddlers too:
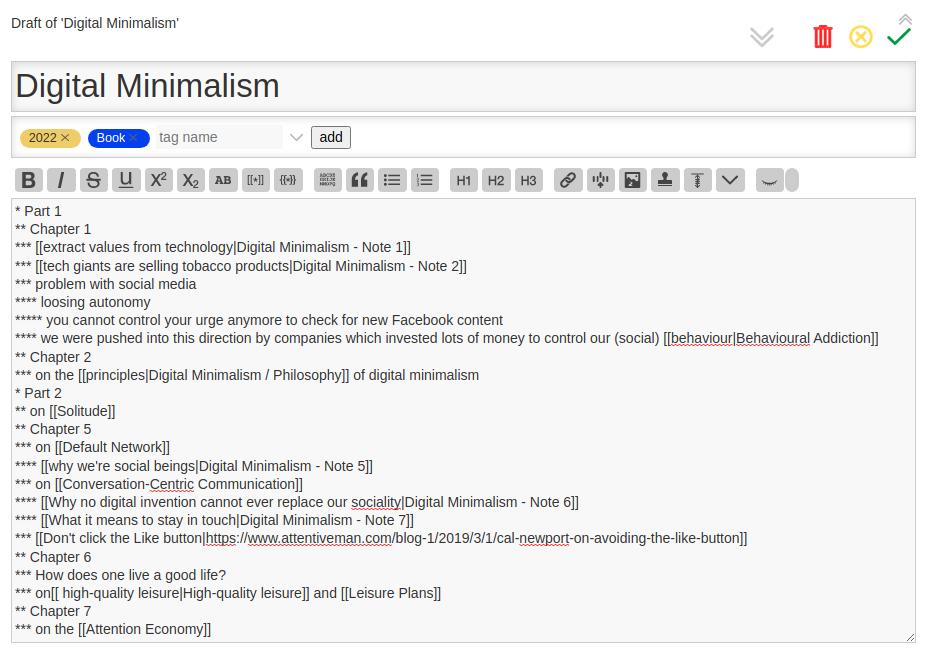
If you pay attention, there are lots of similarities. That’s why I could easily copy and paste most of the ORG content into the tiddlers. As for the rest (source blocks, quotes, examples, sidenotes etc.) manual conversion (or using ox-tiddly ) was necessary.
It was especially this part that slowed me down in my post-reading process mainly because:
- I’m writing my notes in Emacs (using ORG)
- converting to full tiddlywiki syntax takes time
- in some of blog posts (written in ORG) I wanted to include some content from different tiddlers
- I had to convert Tiddlywiki content back to ORG syntax again
This back and forth between ORG/Emacs and Tiddlywiki combined with the fact I was maintaining multiples sources of information (my raw notes in ORG, my own thoughts / processed notes in Tiddlywiki) brought me to org-roam. Not only this, but it also forced me to rethink my note-taking workflow and make adjustments to the whole system.
I’ll explicitly cover org-roam, hugo and ox-hugo in the next part.
Exporting from Tiddlywiki #
As I’ve started exporting my notes from Tiddlywiki I soon realized there are 2 options to do so:
- you could use external standard Unix utilities
- and parse files using
sed,aws& co.
- and parse files using
- but you could also use Tiddlywikis internal templating system to generate data
Export tiddlers #
David Alfonso has done a great job and put together a repository that helps you with the
export of tiddlers. All you need is to export all your tiddlers bundled as one single HTML and
then follow the instructions in the README.
In my Tiddlywiki root directory I had a tiddlywiki.info with a build step to export all tiddlers:
|
|
|
|
Now let’s generate the single HTML file:
|
|
|
|
Generate HTML and meta files #
Once you have generated your single HTML Tiddlywiki file, clone the repository and copy your
file to wiki.html inside the repository’s root folder. Then you can run make to export your tiddlers.
Afterwards, for each tiddler, you will get:
- a
HTMLfile (with the tiddler’s content) - a
metafile (containing header information)
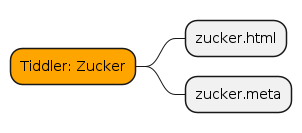
Figure 1: The original tiddler gets exported into one HTML and one meta file.
As an example (for the “zucker” tiddler):
|
|
|
|
And now the meta data:
|
|
|
|
Convert to ORG mode #
The original repository will export by default all tiddlers to markdown. Since pandoc is used
we can also export to ORG mode directly by changing the Makefile.
I’ve created a fork with my own customizations.
Instead of exporting to commonmark we export to markdown first:
|
|
Then for every generated markdown file we
- add
#+to every header line (in the corresponding.metafile) - insert a newline after header lines
- convert the
markdownfile toORGformat
|
|
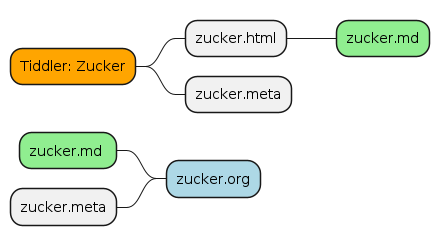
Figure 2: The ORG file consists of the meta file (where every line is prepended by #+) and the corresponding markdown file.
This is how the final ORG file looks like:
|
|
|
|
Extract bookmarks #
I have lots of bookmarks (each one is mapped to one tiddler) tagged in this way:
|
|
|
|
So each bookmarks consists of:
- a name
- a note
- an url
- a title (usually the same as name)
Now we can easily parse these files and create the desired structure. For this purpose I’ve used this tinny Python snippet:
|
|
Used against our bookmark file it will yield:
|
|
|
|
This way we get a nice ORG mode headline with some properties. Now let’s convert all available bookmarks and save into one big file:
|
|
Let’s check how many entries we got:
|
|
|
|
Extract journal entries #
Collect all journal tiddlers and merge them into one big file.
|
|
|
|
Extract books #
This was the most difficult part and I’ll try to explain why. This is how a book tiddler usually looks like (1984):
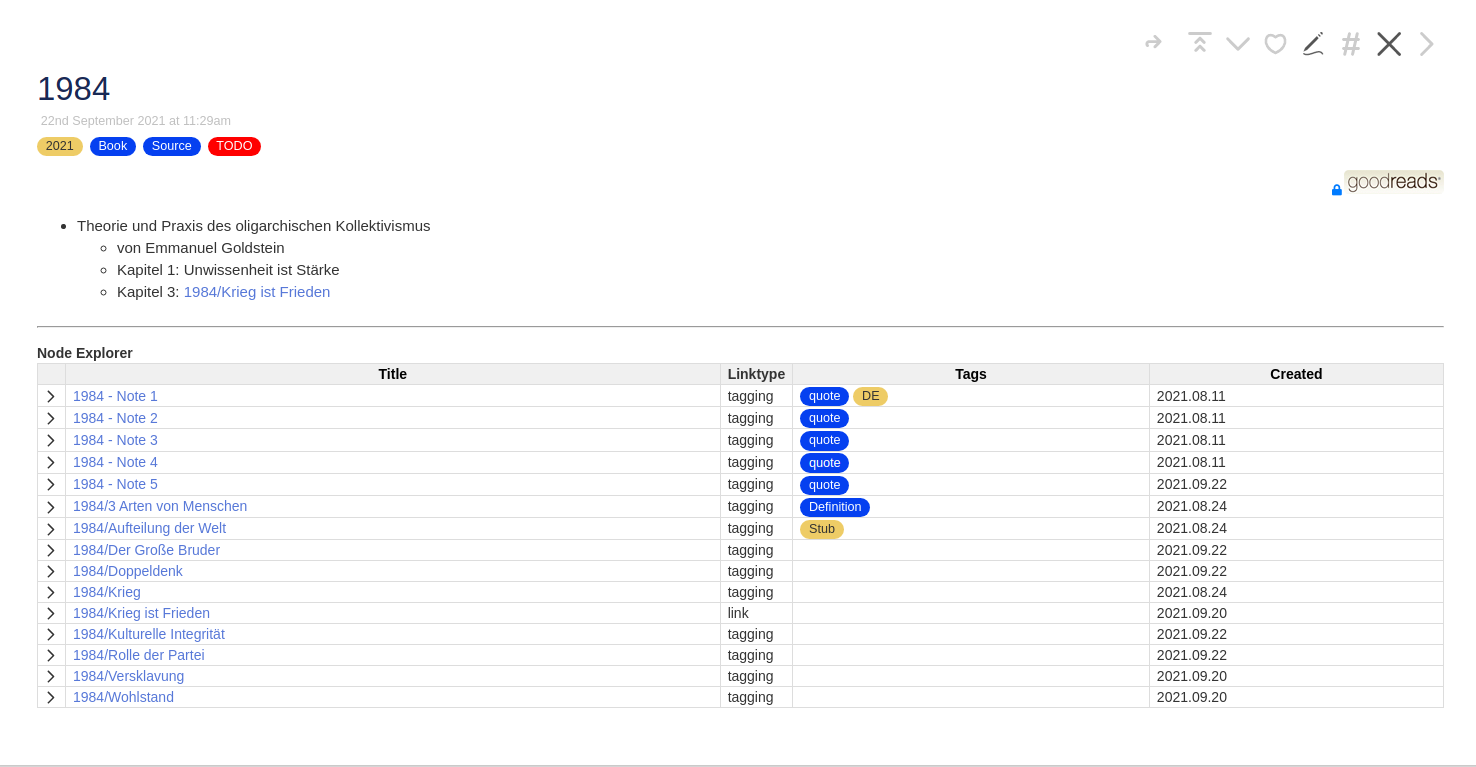
Usually I have some content inside the tiddler but also some additional tiddlers related to the book:
- notes/quotes
- most of the time these are quotes
- Examples:
1984 - Note 1,1984 - Note 2etc.
- subtopics
- for each interesting thought/concept I’ve found in the book I create a new tiddler where the name has following syntax:
<book>/<subtopic>.- I’ve initially read about this idea on Soren’s Zettelkasten and I liked it
- Examples:
- for each interesting thought/concept I’ve found in the book I create a new tiddler where the name has following syntax:
Basically I wanted to merge every tiddler into one ORG file.
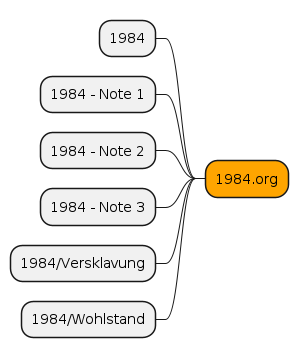
Figure 3: Merge every single tiddler related to 1984 into one big ORG file.
Instead of applying some sed & awk magic, I decided to use Tiddlywikis internal templating
system. The $:/core/templates/static.tiddler.html template for examples defines how a
single tiddler should be exported to its corresponding HTML file:
|
|
We can use the same mechanism to define a template for a book tiddler whenever this has to be exported. But first of all let’s see how a template is used when exporting:
|
|
This is what happens:
- we load the single HTML Tiddlywiki file via
--load - we use
--renderRead more about the RenderCommand. to export a list of tiddlers - as a filter we use
[!is[system]tag[Book]]which means:- give me all non-system tiddlers and from this selection
- give me all tiddlers tagged with
Book
[encodeuricomponent[]addprefix[books/]addsuffix[.org]]handles the file path of tiddler to be exported$$:/vd/templates/render-bookis the name of the template to be used
And now $:/vd/templates/render-book :
|
|
Let’s dissect the snippet fragment by fragment.
Add book content #
|
|
We create a list of tiddlers with following filter: [all[current]] (another way to express we just want the current tiddler).
We then create an ORG mode headline consisting of the field title in the current tiddler ({{!!title}}). Then we add
a FINISHED property using the fields finished_year and finished_month
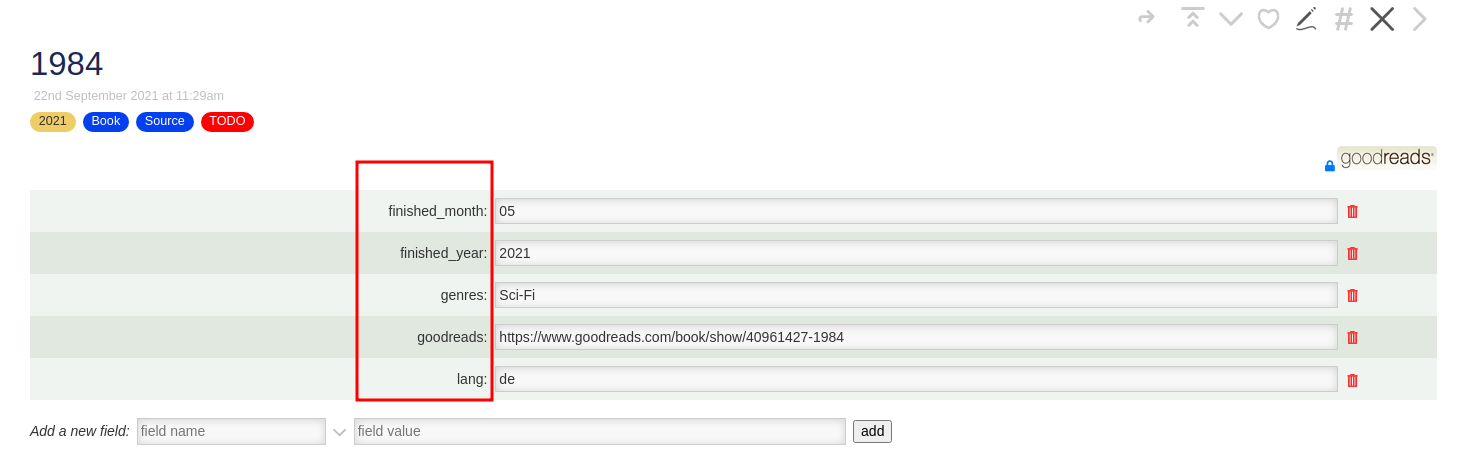
Then I create a sub-heading called Description where I put the tiddler’s content (field text).
Add notes #
|
|
We create a sub-heading called Notes where we add additional sub-nodes. For this to work we create again
a list of tiddlers where we apply the filter: [subfilter<childrenFilter>]. childrenFilter is defined
at the top:
-
prefix<currentTiddler>- We focus only on the tiddlers which have the
currentTiddleras a prefix. - if
currentTiddleris 1984, then this will match1984 - Note 11984/Wohlstand
- We focus only on the tiddlers which have the
-
!title<currentTiddler>- This makes sure we don’t match ourself (the
currentTiddler)
- This makes sure we don’t match ourself (the
-
!tag[quote]- Match only tiddlers which don’t have tag
quote
- Match only tiddlers which don’t have tag
-
sortan[]- Sort list of tiddlers by text field The sortan Operator
For the sub-heading we then add some properties: CREATED (field created) and TAGS (field tags).
Add quotes #
|
|
Also here we create a sub-heading called Quotes and underneath we create additional sub-nodes
for the quotes. As for Notes we have a subfilter (quotesFilter):
- it matches all tiddlers which have the currentTiddler’s title as a prefix
- AND are tagged by
quote.
Put everything together #
Now that we have a template let’s have a look at the output:
|
|
$:/vd/templates/render-book template.
And this is what we get:
|
|
|
|
I think that’s pretty good. And this is the final result.

I intentionally didn’t add content in the Notes section to the sub-nodes. In the next post
I’ll explain how I managed to quickly review my notes using Emacs and some Elisp and add content on the go.
This article is part of a series.
- Part 1: This Article
- Part 2: Migrate Tiddlywiki to org-roam - Part 2: org-roam and hugo