This article is part of a series.
In the first part of this series I’ve outlined the main factors for moving my digital
garden / braindump / Zettelkasten to org-roam and which factors have facilitated this
decision. In the 2nd part I will expand more how I’ve built the new brainfck.org using
hugo, ox-hugo and org-roam.
Extracting tiddlers from my Tiddlywiki setup was only the first step towards a Second
Brain using org-roam. Since I’m a clear advocate for public digital gardens, I didn’t want
to keep my notes only for my self. Having built several sites with hugo already, it felt
natural to chose it as a publishing system for my new setup.
In the following I will try to emphasize some important challenges I have experienced
while migrating Tiddlywiki tiddlers to org-roam, creating and editing the content and finally
export it to HTML via hugo.
hugo
#
As a starting point I have used Jethro’s braindump repository especially for the Elisp part.
You can also have a look at my own repository.
First of all I’m a big fan of Makefiles:
1
2
3
4
|
export:
python build.py
dev:
hugo server -b http://127.0.0.1:1315/ -v --port 1315 --noHTTPCache --cleanDestinationDir --debug --gc
|
Code Snippet 1:
Makefile
I use python
I plan to switch to some Makefile only version in the future.
for the export task:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
#!/usr/bin/env python
import glob
from pathlib import Path
# files = glob.glob("org/books/done/*.org") + glob.glob("org/topics/*.org") + glob.glob("org/journal/*.org")
with open('build.ninja', 'w') as ninja_file:
ninja_file.write("""
rule org2md ❶
command = emacs --batch -l ~/.emacs.d/init.el -l publish.el --eval '(brainfck/publish "$in")'
description = org2md $in
""")
# Pages ❷
files = glob.glob("org/*.org")
for f in files:
path = Path(f)
output_file = f"content/pages/{path.with_suffix('.md').name}"
ninja_file.write(f"""
build {output_file}: org2md {path}
""")
# Books ❸
files = glob.glob("org/books/done/*.org")
for f in files:
path = Path(f)
output_file = f"content/books/{path.with_suffix('.md').name}"
ninja_file.write(f"""
build {output_file}: org2md {path}
""")
# Journal ❹
files = glob.glob("org/journal/*.org")
for f in files:
path = Path(f)
output_file = f"content/journal/{path.with_suffix('.md').name}"
ninja_file.write(f"""
build {output_file}: org2md {path}
""")
# Topics ❺
files = glob.glob("org/topics/*.org")
for f in files:
path = Path(f)
output_file = f"content/topics/{path.with_suffix('.md').name}"
ninja_file.write(f"""
build {output_file}: org2md {path}
""")
import subprocess
subprocess.call(["ninja"]) ❻
|
Code Snippet 2:
build.py
This small snippet generates ❶ build statements for ninja ❻. The build.ninja file will contain something similar to:
1
2
3
4
5
6
7
8
9
10
11
|
rule org2md
command = emacs --batch -l ~/.emacs.d/init.el -l publish.el --eval '(brainfck/publish "$in")'
description = org2md $in
build content/pages/index.md: org2md org/index.org
build content/pages/bookshelf.md: org2md org/bookshelf.org
build content/books/breath_the_new_science_of_a_lost_art.md: org2md org/books/done/breath_the_new_science_of_a_lost_art.org
[...]
|
Code Snippet 3:
build.ninja
For each folder in my org-roam-directory (pages ❷, books ❸, journal ❹, topics ❺)
Each build command consists of org2md which internally calls publish.el:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
(require 'package)
(package-initialize)
(setq package-archives '(("melpa" . "https://melpa.org/packages/")
("org" . "http://orgmode.org/elpa/")))
(require 'find-lisp)
(require 'ox-hugo)
;; https://github.com/kaushalmodi/ox-hugo/issues/500#issuecomment-1006674469
(defun replace-in-string (what with in)
(replace-regexp-in-string (regexp-quote what) with in nil 'literal))
(defun zeeros/fix-doc-path (path) ❸
;; (replace-in-string "../../topics/" "" (replace-in-string "../../topics/" "" path)
(replace-in-string "../../topics/" "../topics/" path)
(replace-in-string "../books/done/" "../books/" path)
(replace-in-string "books/done/" "books/" path)
)
❹
(advice-add 'org-export-resolve-id-link :filter-return #'zeeros/fix-doc-path)
(defun brainfck/publish (file) ❶
(with-current-buffer (find-file-noselect file)
(setq-local org-hugo-base-dir "/cs/priv/repos/roam")
;; (setq-local org-hugo-section "posts")
(setq-local org-export-with-tags nil)
(setq-local org-export-with-broken-links t)
(add-to-list 'org-hugo-special-block-type-properties '("sidenote" . (:trim-pre t :trim-post t)))
(setq org-agenda-files nil)
(let ((org-id-extra-files (directory-files-recursively org-roam-directory "\.org$")))
(org-hugo-export-wim-to-md)))) ❷
|
Code Snippet 4:
publish.el
The main function brainfck/publish ❶ basically calls org-hugo-export-wim-to-md ❷ which
will “export the current subtree/all subtrees/current file to a Hugo post”. Before doing
so some local variables are set and org-id-extra-files is populated with all available ORG
roam file paths. This variable holds all files/paths where ORG should search for IDs.
And because some IDs couldn’t be resolved properly
Obviously there is a bug.
I had to use some “hook” ❹ for rewriting ❸
some file paths within the generated markdown files.
For testing purposes you can call the publish.el with just one argument:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
$ emacs --batch -l ~/.emacs.d/init.el -l publish.el --eval "(brainfck/publish \"org/books/done/building_microservices_2nd_edition.org\")"
[...]
Loading gnus (native compiled elisp)...
Ignoring ’:ensure t’ in ’lsp-ui’ config
Ignoring ’:ensure t’ in ’json-snatcher’ config
Initializing org-roam database...
Clearing removed files...
Clearing removed files...done
Processing modified files...
Processing modified files...done
Clearing removed files...
Clearing removed files...done
Processing modified files...
Processing modified files...done
org-super-agenda-mode enabled.
[...]
Loading linum (native compiled elisp)...
768 files scanned, 410 files contains IDs, and 426 IDs found.
[ox-hugo] Exporting ‘Building Microservices (2nd edition)’ (building_microservices_2nd_edition.org)
|
Code Snippet 5:
Example call for publish.el
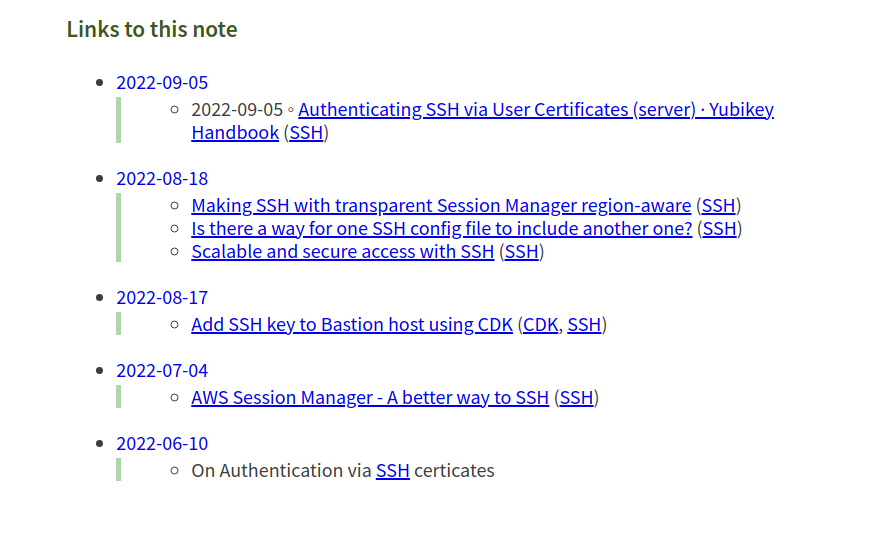
Backlinks
#
Backlinks are an essential feature that let you visualize inter-connected content.
Whenever I set a link to another org-roam node in an ORG file, the exported markdown content will look like this:
1
2
3
|
...
- 2022-09-05 ◦ [Authenticating SSH via User Certificates (server) · Yubikey Handbook](https://ruimarinho.gitbooks.io/yubikey-handbook/content/ssh/authenticating-ssh-via-user-certificates-server/) ([SSH]({{< relref "../topics/ssh.md" >}}))
...
|
Code Snippet 6:
Excerpt from my journal entry
2022-09-05
You can see I’ve set a reference to SSH which looks like this:
1
|
[SSH]({{< relref "../topics/ssh.md" >}})
|
The question is: For a given node/topic how can we find all nodes containing a link to current node? Well we can parse
content and actually search for that specific topic. In hugo you can do something like this:
1
2
3
4
5
6
7
8
9
|
...
{{ $re := printf `["/(]%s.+["/)]` .page.File.LogicalName | lower }} ❶
{{ $backlinks := slice }}
{{ range where site.RegularPages "RelPermalink" "ne" .page.RelPermalink }}
{{ if (findRE $re .RawContent 1) }} ❷
{{ $backlinks = $backlinks | append . }} ❸
{{ end }}
{{ end }}
|
Code Snippet 7:
hugo partial to scan for backlinks for a given page
- ❶
.page.File.LogicalName is sth like ssh.md
`["/(]%s.+["/)]` .page.File.LogicalName | lower will then yield `["/(]ssh.md.+["/)]`
- ❷ find any lines containing the logical file name (
ssh.md) inside parantheses
- examples: [ssh.md], “ssh.md”, (ssh.md)
- ❸ if we have any matches add page to
$backlinks slice
Let’s have a look at the regular expression. Therefore I’ll use some Go snippets to test the regexp:
You can also play here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"fmt"
"regexp"
)
func main() {
pattern := regexp.MustCompile(`(?i)["/(]ssh.md.+["/)]`)
inputs := []string{
"[SSH]({{< relref \"../topics/ssh.md\" >}})",
"[we mention SSH in the link description]({{< relref \"../topics/ssh.md\" >}})",
"[no mention at all]({{< relref \"../topics/ssh.md\" >}})",
"[no mention at all, also in the ref]({{< relref \"../topics/other.md\" >}})",
}
for _, i := range inputs {
matches := pattern.FindAllString(i, -1)
if len(matches) > 0 {
fmt.Println(matches)
}
}
}
|
Code Snippet 8:
Small Go utility to test our regexp against some common use cases.
1
2
3
|
[/ssh.md" */>}})]
[/ssh.md" */>}})]
[/ssh.md" */>}})]
|
Once we have populated the backlinks slice with a list of pages backlinking to the current page
we can then search inside the page content for exactly the lines containing the backlink:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
{{ $content_re := printf `.*\[%s\].*` .page.Title }} ❶
...
{{ range $backlinks }}
{{ $matches := findRE $content_re .RawContent}}
<li class="lh-copy"><a class="link f5" href="{{ .RelPermalink }}">{{ .Title }}</a></li>
{{ if $matches }} ❷
<blockquote>
{{ range $matches }}
{{ . | markdownify }}
{{ end }}
</blockquote>
{{ end }}
{{ end }}
...
|
- We search for any line containing the current page title (❶)
- If we have any matches we call
markdownify against that line (❷)
And this is how the result looks like:
For the sake of completeness here’s the full backlinks partial:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
{{ $re := printf `["/(]%s.+["/)]` .page.File.LogicalName | lower }}
{{ $content_re := printf `.*\[%s\].*` .page.Title }}
{{ $backlinks := slice }}
{{ range where site.RegularPages "RelPermalink" "ne" .page.RelPermalink }}
{{ if (findRE $re .RawContent 1) }}
{{ $backlinks = $backlinks | append . }}
{{ end }}
{{ end }}
<hr>
{{ if gt (len $backlinks) 0 }}
<div class="bl-section">
<h3>Links to this note</h3>
<div class="backlinks">
<ul>
{{ range $backlinks }}
{{ $matches := findRE $content_re .RawContent}}
<li class="lh-copy"><a class="link f5" href="{{ .RelPermalink }}">{{ .Title }}</a></li>
{{ if $matches }}
<blockquote>
{{ range $matches }}
{{ . | markdownify }}
{{ end }}
</blockquote>
{{ end }}
{{ end }}
</ul>
</div>
</div>
{{ else }}
<div class="bl-section">
<h4>No notes link to this note</h4>
</div>
{{ end }}
|
Code Snippet 9:
hugo partial for generating backlinks
As a last step I had to make use of this partial in my single.html template:
1
2
3
4
5
6
|
...
<div class="lh-copy post-content">{{ .Content }}</div>
{{ partial "backlinks.html" (dict "page" .) }}
...
|
Code Snippet 10:
In order to use the backlinks partial, you'll have to embed in your single template.
Section pages
#
Group topics by capital letter
#
For the topics page I wanted to group my topics by the first letter. Therefore in layouts/topics/list.html I’ve inserted following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
{{ define "main" }}
<main class="center mv4 content-width ph3">
<h1 class="f2 fw6 heading-font">{{ .Title }}</h1>
<div class="post-content">
{{ .Content }}
<!-- create a list with all uppercase letters -->
{{ $letters := split "ABCDEFGHIJKLMNOPQRSTUVWXYZ" "" }}
<!-- range all pages sorted by their title -->
{{ range .Data.Pages.ByTitle }}
<!-- get the first character of each title. Assumes that the title is never empty! -->
{{ $firstChar := substr .Title 0 1 | upper }}
<!-- in case $firstChar is a letter -->
{{ if $firstChar | in $letters }}
<!-- get the current letter -->
{{ $curLetter := $.Scratch.Get "curLetter" }}
<!-- if $curLetter isn't set or the letter has changed -->
{{ if ne $firstChar $curLetter }}
<!-- update the current letter and print it -->
<!-- https://gohugohq.com/howto/hugo-create-first-letter-indexed-list/ -->
</ul>
{{ $.Scratch.Set "curLetter" $firstChar }}
<h1>{{ $firstChar }}</h2>
<ul class="list-pages">
{{ end }}
<li class="">
<a class="title" href="{{ .Params.externalLink | default .RelPermalink }}">{{ .Title }}</a>
</li>
{{ end }}
{{ end }}
</div>
</main>
{{ partial "table-of-contents" . }}
<div class="pagination tc db fixed-l bottom-2-l right-2-l mb3 mb0-l">
{{ partial "back-to-top.html" . }}
</div>
{{ end }}
|
Code Snippet 11:
Define how to show list of topics (group by first letter)
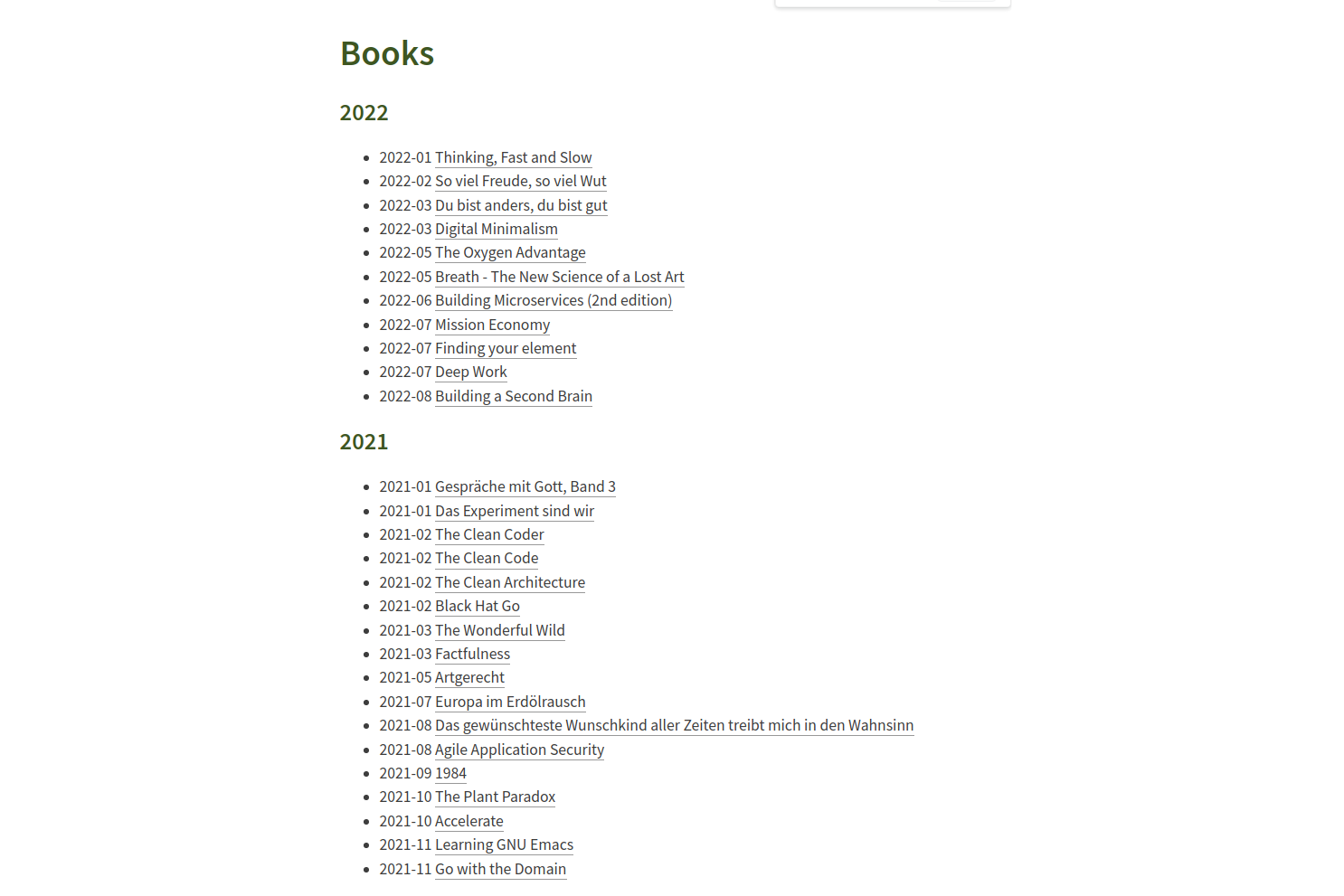
Group books by year and month
#
Following snippet will show a list of books grouped by year. For each year each book will be shown
along with the date in yyyy-mm format.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
{{ define "main" }}
<main class="center mv4 content-width ph3">
<h1 class="f2 fw6 heading-font">{{ .Title }}</h1>
{{ .Content }}
{{ range (where .Site.RegularPages "Type" "in" (slice "books")).GroupByDate "2006" }}
<h2>{{ .Key }}</h2>
<ul class="list-pages">
{{ range .Pages.ByDate }}
<li class="lh-copy">
{{ $curDate := .Date.Format (.Site.Params.dateFormat | default "2006-02" ) }}
<span class="date">{{ printf "%s " (slicestr $curDate 0 7 ) }}</span>
<a class="title" href="{{ .Params.externalLink | default .RelPermalink }}">{{ .Title }}</a>
</li>
{{- end -}}
</ul>
{{ end }}
</main>
<div class="pagination tc db fixed-l bottom-2-l right-2-l mb3 mb0-l">
{{ partial "back-to-top.html" . }}
</div>
{{ end }}
|
org-roam
#
As a complete org-roam novice I’ve found Getting Started with Org Roam - Build a Second
Brain in Emacs (notes) to be a quite good introduction. It will give you enough background
to get you started with org-roam. For more advanced topics you could also read 5 Org Roam
Hacks for Better Productivity in Emacs or check out my org-roam topic for more resources.
By default all org-roam nodes are placed within the same directory. However, one big directory
for all notes didn’t resonate with me at all. I came up with following hierarchy inside org-roam-directory:
Check out the org folder inside the roam repository.
- org/
This is the root org-roam directory.
- books/
-
this is where all books (stored as individual ORG files) should be located at
-
I consider these files my literature notes
“A literature note is a source reference in a reference manager, optionally with one
or more attached notes. The term ‘literature note’ derives from the note cards on
which Niklas Luhmann, the prolific sociologist and originator of the Zettelkasten
Method, recorded bibliographic references (Ahrens, 18).” – zettelkasten.de
-
thoughts and concepts found within one book may remain here
- or at same time I move it to an individual topic
-
quotes are now stored in the same (book ORG mode) file (example)
- topics/
- all individual topics are stored here
- I don’t distinguish between collection nodes, thoughts and concepts
- journal/
- files inside this folder are daily journals
- each file name has following format:
YYYY-MM-DD.org
- this is where I usually store thoughts, links which I haven’t categorized yet
- or put into the right topic
- notes/
- I don’t use this section yet (I’m also not sure if it’s needed at all)
- This category relates to notes writen in my own words
- can link to concepts inside a book
- can refer to multiple topics
Capture templates
#
For rapid capture org-roam uses pre-defined capture templates
You can also store templates in Org files.
(similar to ORG mode capture templates) whenever a new entry (topic, book, note, quote etc.) should be added. These are mine:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
(org-roam-capture-templates
'(("d" "default" plain
"%?"
:if-new (file+head "topics/${slug}.org" "#+title: ${title}\n") ❶
:unnarrowed t)
("j" "Journal" plain "%?" ❷
:if-new (file+head "journal/%<%Y-%m-%d>.org"
"#+title: %<%Y-%m-%d>\n#+filetags: journal\n#+date: %<%Y-%m-%d>\n")
:immediate-finish t
:unnarrowed t)
("b" "book" plain "%?" ❸
:if-new
(file+head "books/${slug}.org" "#+title: ${title}\n#+filetags: book\n")
:immediate-finish t
:unnarrowed t)
))
|
Code Snippet 12:
ORG Roam capture templates
Per default ❶ every new entry is a topic. Additionally I want every journal ❷ file to contain several meta information (properties) (like #+date and #+filetags).
Last but not least I want every book ❸ to be stored under <ORG Roam directory root>/books/.
Emacs Kung Fu
#
As I was transitioning content from multiple folders into the org-roam directory
I’ve used Emacs editing capabilities to edit and create content using small Elisp snippets and macros. Let’s explore some workflows.
Insert content at point
#
Whenever I was adding content (e.g. from sub-tiddlers) to main topic nodes (previsouly main tiddler in Tiddlywiki), I wanted to quickly jump between directories where my tiddlers
were exported as org content.
1
2
3
4
5
6
7
8
9
10
|
(defun dorneanu/roam-insert (dir) ❶
(let* (
(filename (read-file-name "filename: " dir nil nil nil)))
(insert-file-contents filename))
)
;; Define global key bindings ❷
(global-set-key (kbd "C-c m b") (lambda () (interactive) (dorneanu/roam-insert "/cs/priv/repos/brainfck.org/tw5/output/books")))
(global-set-key (kbd "C-c m t") (lambda () (interactive) (dorneanu/roam-insert "/cs/priv/repos/tiddlywiki-migrator/org_tiddlers")))
(global-set-key (kbd "C-c m .") (lambda () (interactive) (dorneanu/roam-insert "/cs/priv/repos/roam/org/topics/")))
|
Therefore I’ve defined a function ❶ which reads a file content after this has been
selected. The (temporary) key bindings ❷ allowed me to jump between following folders
and insert content quickly:
/cs/priv/repos/brainfck.org/tw5/output/books
- This is where I’ve exported my book tiddlers along with their correspondig sub-tiddlers (read the first post for the explanations regarding books and their sub-tiddlers)
/cs/priv/repos/tiddlywiki-migrator/org_tiddlers
- This is where all tiddlers got exported to initially
/cs/priv/repos/roam/org/topics
- this is the root org-roam folder for topics
Add structure template for quotes
#
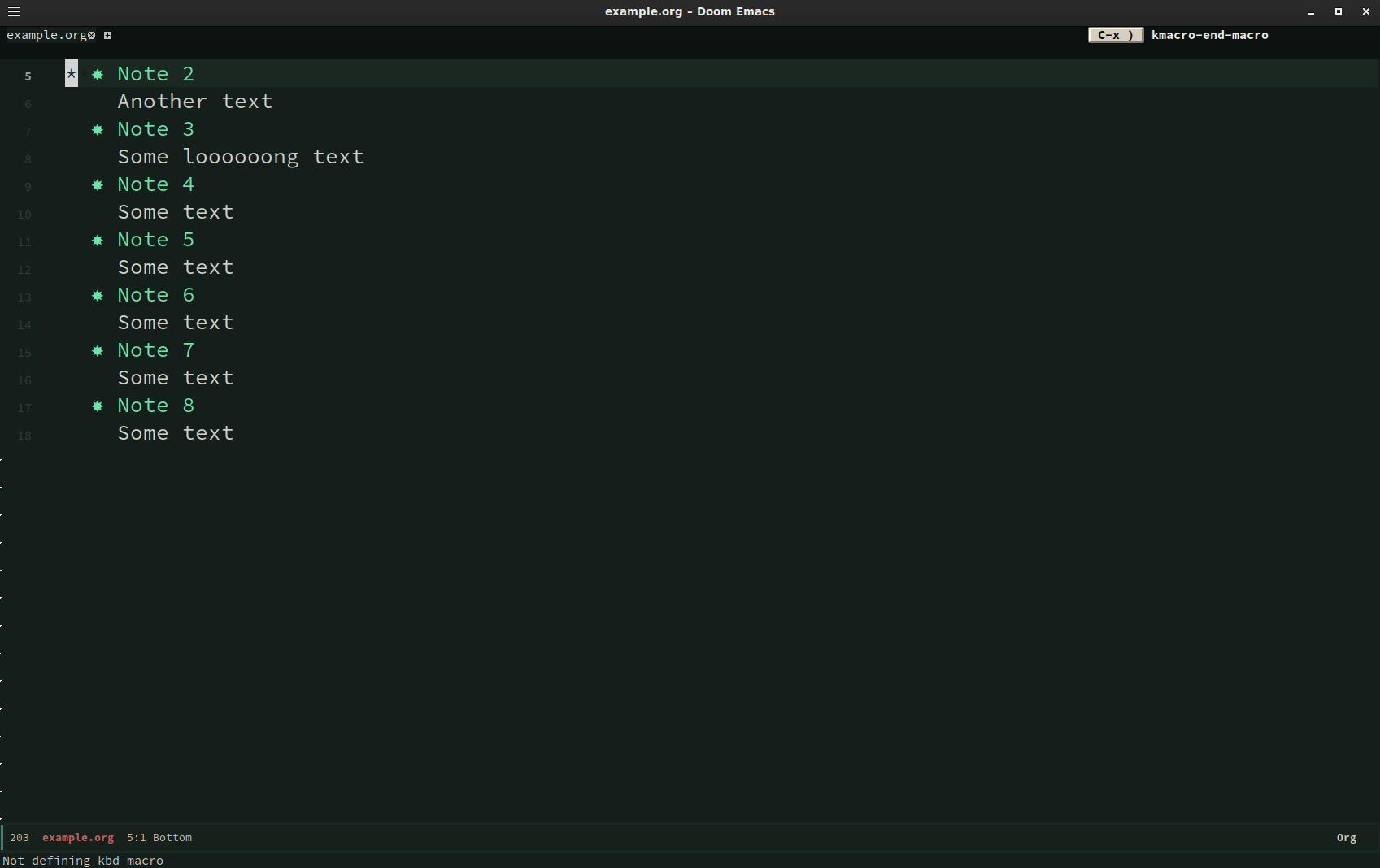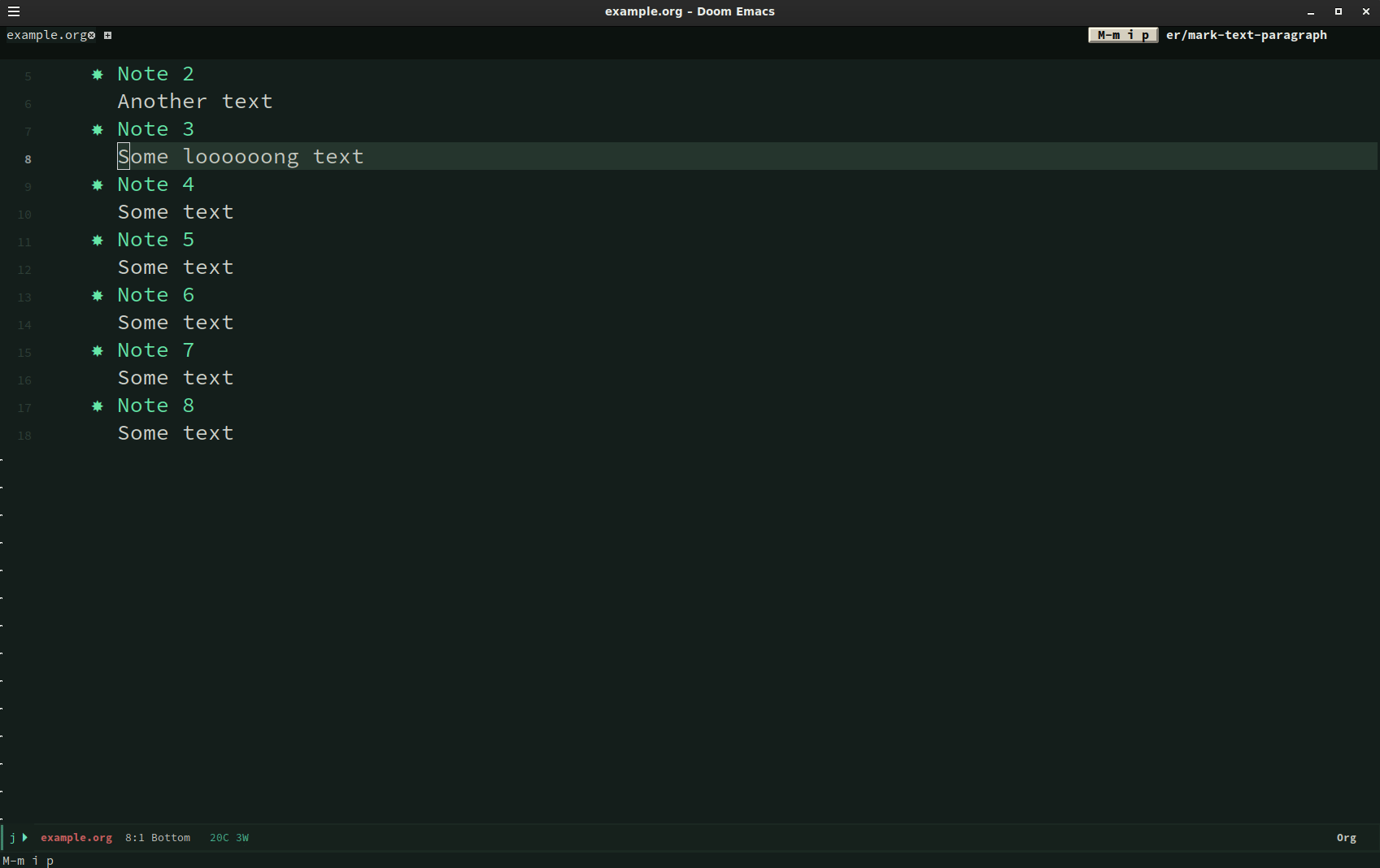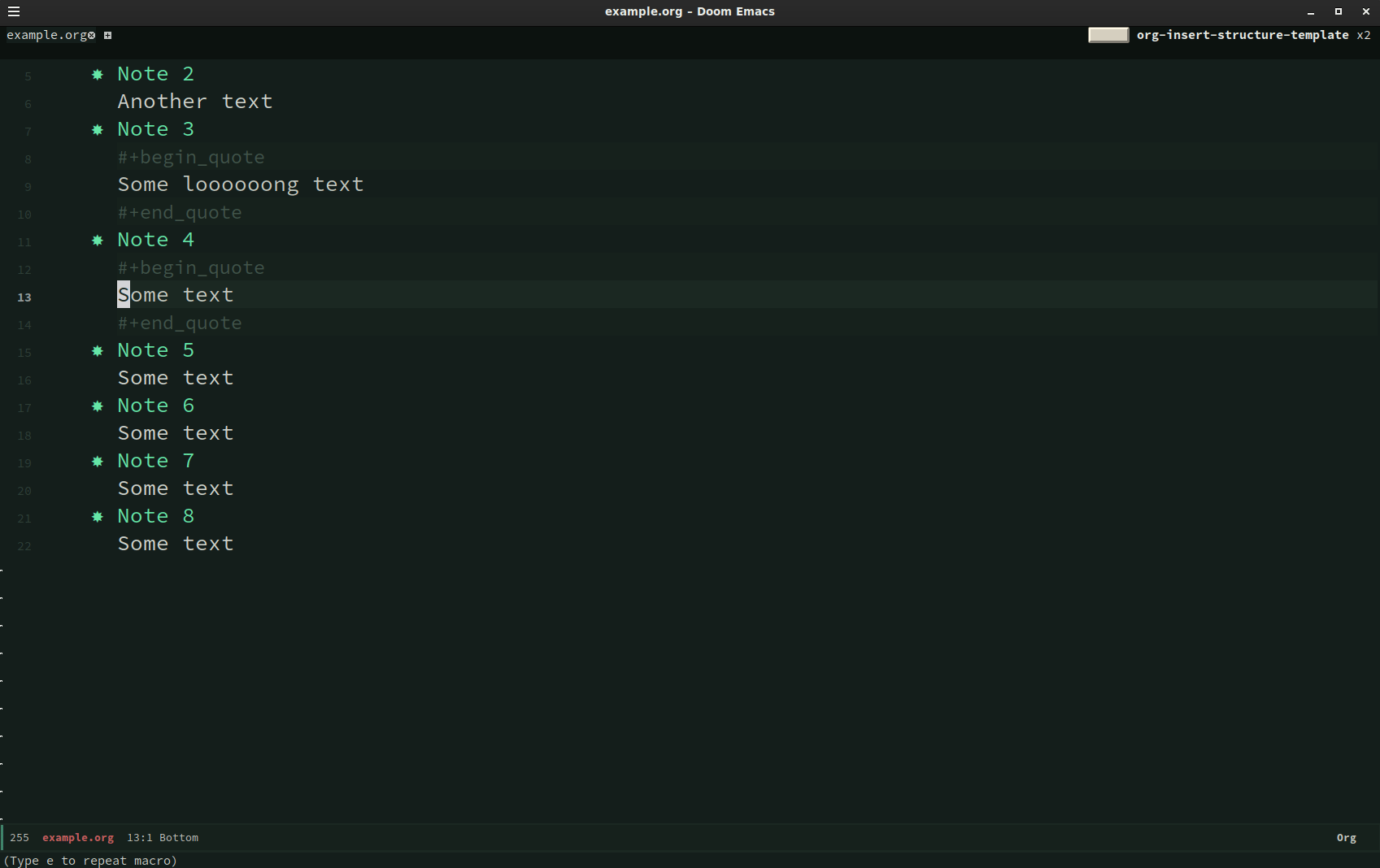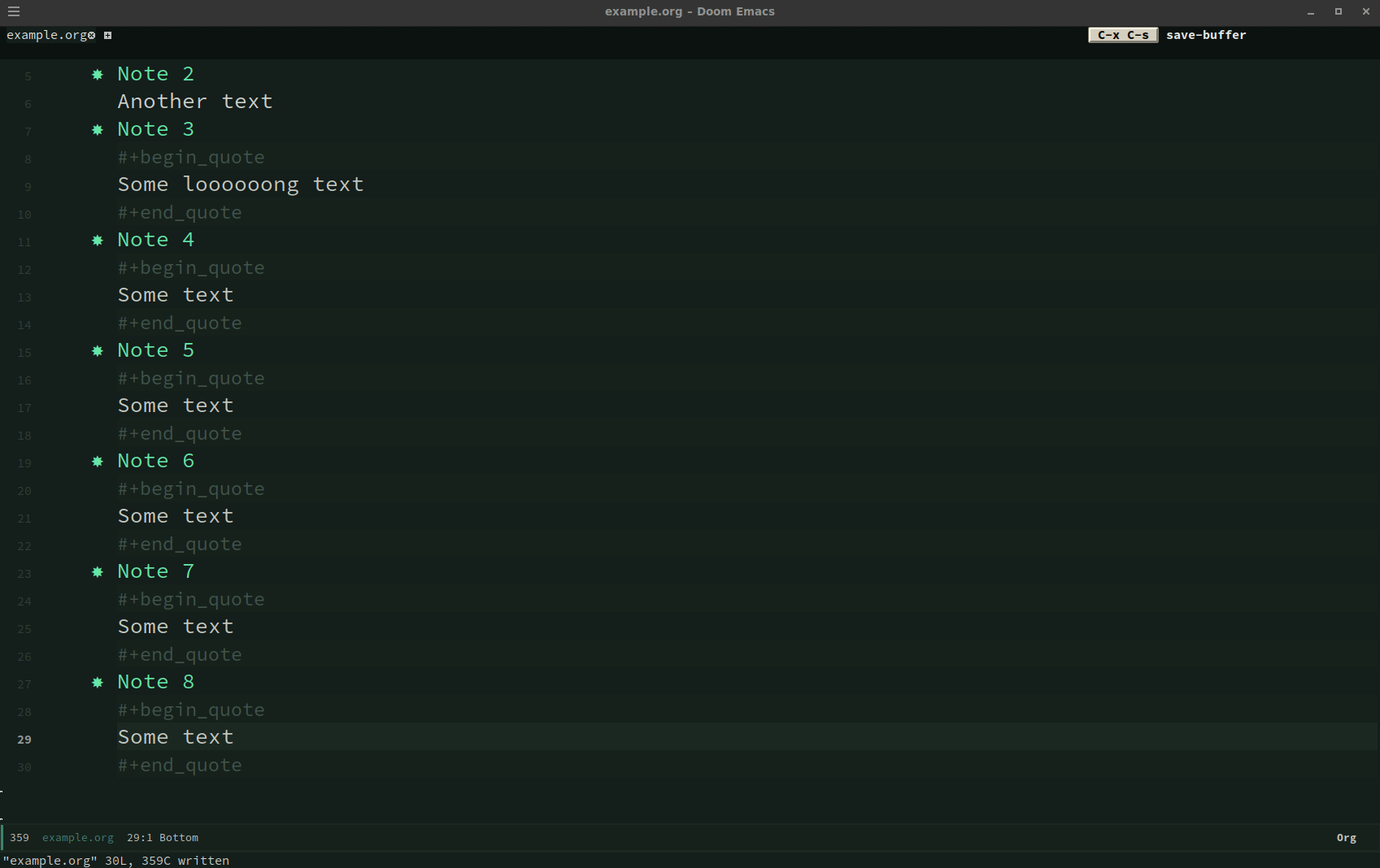
Let’s say you have following ORG content:
1
2
3
4
5
6
7
8
|
* Book title
** Notes
*** Note 1
Some text
*** Note 2
Another text
*** Note 3
Some loooooong text
|
How can you easily put the content underneath each note (Note 1, Note 2, Note 3) into
quote blocks? Here is where macros came to my rescue. With my cursor on Note 1 I typed:
C-x (
kmacro-start-macro- start macro
g j
outline-forward-same-level- go to next headline (in the same level)
j (move cursor to next line)M-m i p
mark-paragraph- mark whole paragraph
C-c C-,
org-insert-structure-template- wrap marked region into …
q
C-x )
kmacro-end-macro- end macro sequence
Here is some screencast:
Conclusion
#
In retrospect I think I’ve spent way to much pretious lifetime for this project - and I’m
not finished yet. There are still to many empty topics (no content at all) and links
pointing to nirvana (e.g. links in old Tiddlywiki syntax). However, I think, the effort
will pay off in the long run! In fact I already feel more productive as I’m able to quickly
search for notes (in books, topics, journals etc.) and create these on-the-fly if not existant.
I’ve definitely improved my Emacs Kung Fu™ and learned even more about its editing
features (macros!). I also hope org-roam will help me produce even more content and
prevent me from just collecting random notes.
This article is part of a series.